1. Scrapy框架简介
- Scrapy是一个python编写的、快速、强大的爬虫框架。有如下特点:
1. 基于Twisted的异步、非阻塞的网络请求,不用等待上一个网络请求结束才开始下一个请求。
2. 基于Xpath和CSS从HTML和XML数据源中提取数据。
3. 支持将数据导出为Json/CSV/XML格式。
4. 交互式命令行工具创建爬虫、开始爬取、分析爬取数据、调试、部署爬虫。
2. scrapy爬取流程
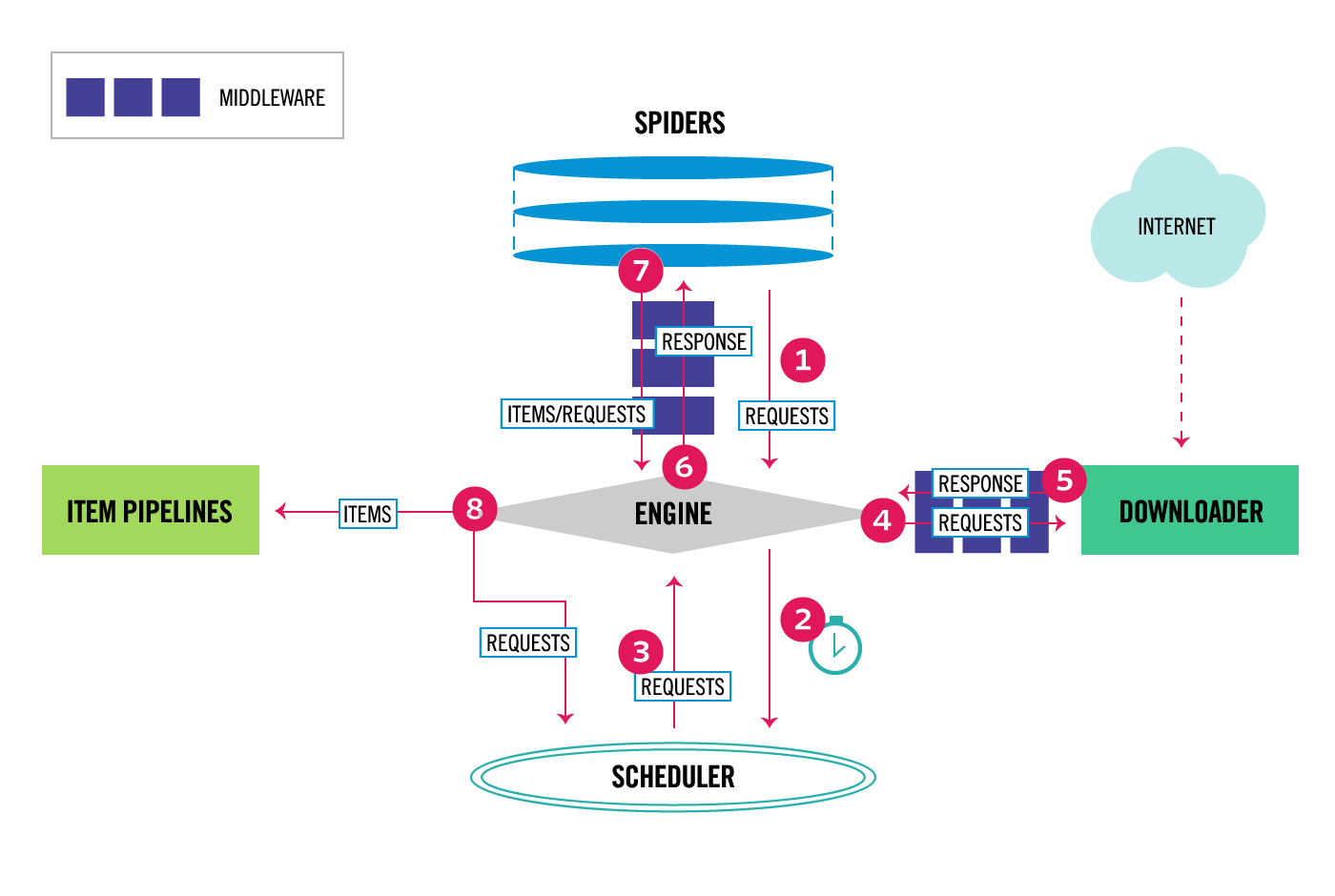
- 八步爬取流程
- scrapy通过自带的shell命令生成爬虫项目,以及启动爬虫。操作步骤如下:
第一步: 生成爬虫项目1
scrapy startproject tutorial
项目目录结构如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14tutorial/
scrapy.cfg # deploy configuration file
tutorial/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items definition file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py
第二步:生成爬虫类,进入tutorial目录,执行下面命令1
scrapy genspider quotes quotes.toscrape.com
这里,quotes爬虫名称,quotes.toscrape.com是要爬取的网站域名。
第三步:编写爬虫类,编辑quotes.py文件如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split("/")[-2]
filename = 'quotes-%s.html' % page
with open(filename, 'wb') as f:
f.write(response.body)
self.log('Saved file %s' % filename)
这里urls中的是起始爬取url,start_requests方法根据url产生请求,parse方法解析返回的response,并将body写入文件。
第四步:运行爬虫1
scrapy crawl quotes
4. scrapy核心类介绍
- scrapy.spiders.Spider:爬虫基类,所有自定义爬虫都要继承它。关键属性和方法如下:
- name:爬虫名字
- start_urls:起始爬取url列表
- start_requests():产生初始爬取的、可迭代的Request对象
- parse(response): 处理Response的回调函数
- log(message): 产生日志
- from_crawler(crawler, args, *kwargs):创建爬虫的类方法
- scrapy.selector.Selector: 基于lxml库的数据提取器类
- xpath(query): 根据xpath字符串查询节点
- css(query)
- extract():返回字符串列表。
- re(regex)
- scrapy.item.Item: 通用的数据容器类
- Field:指定元数据的类
- fields:包含所有field的字典
- scrapy.loader.ItemLoader:提取item的类
- load_item()
- Item Pipeline: 对爬取数据构造的Item对象进行后续清洗的类,通常需要实现以下方法。
- process_item(self, item, spider)
- open_spider(self, spider)
- close_spider(self, spider)
- from_crawler(cls, crawler)
- scrapy.exporters.BaseItemExporter:导出item到外部存储,支持Json、CSV、XML,通常和Item Pipeline结合使用。
- start_exporting()
- export_item(item)
- finish_exporting()
Item Pipeline和Item Exporter结合的示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29from scrapy import signals
from scrapy.exporters import XmlItemExporter
class XmlExportPipeline(object):
def __init__(self):
self.files = {}
@classmethod
def from_crawler(cls, crawler):
pipeline = cls()
crawler.signals.connect(pipeline.spider_opened, signals.spider_opened)
crawler.signals.connect(pipeline.spider_closed, signals.spider_closed)
return pipeline
def spider_opened(self, spider):
file = open('%s_products.xml' % spider.name, 'w+b')
self.files[spider] = file
self.exporter = XmlItemExporter(file)
self.exporter.start_exporting()
def spider_closed(self, spider):
self.exporter.finish_exporting()
file = self.files.pop(spider)
file.close()
def process_item(self, item, spider):
self.exporter.export_item(item)
return itemscrapy.http.Request:Http请求类,由Downloader执行,返回Response
- scrapy.http.FormRequest(url, formdata): Post请求类,formdata是填充表单数据的字典。
- scrapy.http.Response:Http响应类
- urljoin(url): 根据相对url和response的url构造绝对url
- follow(url, callback): 根据url产生Request对象
- scrapy.linkextractors.LinkExtractor: 提取response中的链接
- extrack_links()
- scrapy.crawler.CrawlerProcess: 同一个进程内运行多个爬虫类
- scrapy.crawler.CrawlerRunner: 跟踪、管理、运行多个爬虫的工具类
- scrapy.downloadermiddlewares.DownloaderMiddleware: 位于Engine类和Downloader类之间,处理request和response,需要在settings.py中配置DOWNLOADER_MIDDLEWARES项,包含如下内置的子类:
- CookiesMiddleware
- DownloadTimeoutMiddleware
- HttpCompressionMiddleware
- RobotsTxtMiddleware
- scrapy.spidermiddlewares.SpiderMiddleware: 位于Engine类和Spider类之间,需要在settings.py中配置SPIDER_MIDDLEWARES项,包含如下内置的子类:
- DepthMiddleware
- HttpErrorMiddleware
