1. A3C(Asynchronous Advantage Actor Critic)算法背景介绍
A3C算法[1]由DeepMind在2015年提出,基于Actor-Critic框架(参考下文),并且通过异步并行训练多个agent的方式,在Atari 2600、TORCS、MuJoCo等视频游戏中都取得了优异的效果。此外,A3C既能适应于离散动作空间的控制,也能适应于连续动作空间的控制。
2. Actor-Critic(行动家-评论家)算法介绍
- 结合使用强化学习中经典的值函数方法和策略梯度方法,所谓的Actor即是策略输出函数,根据agent的状态state产生输出动作action,直观上可以认为它作为大脑来控制agent的行动;Critic即为每个状态的值函数,根据训练过程中获得的历史回报reward来自我调整,同时影响Actor的训练。
- 论文中的Actor和Critic都使用卷积神经网络来近似,两者共享相同的卷积层,但对应于不同的输出。
2.1 策略网络
- $\pi(a|s, \theta)$即为策略函数,根据状态s直接输出动作a,$\theta$是需要优化的参数,优化目标是使得好的策略的出现概率高,坏的策略的出现概率低。
- 根据策略梯度定理,可以得到$\theta$的更新公式为:$\theta \leftarrow \theta + (\sum\limits_{t=1}^{T}\triangledown_{\theta}log\pi(a_{t}|s_{t}; \theta))(\sum\limits_{t=1}^{T}r(s_{t}, a_{t}))$,但直接这样做带来的问题是高方差、学习效率低,因为这里的梯度值对于所有action来说都是正的。
- 在Actor-Critic框架中,引入了基于状态值函数估计得到的Advantage函数$A^{\pi}(s,a)=r(s,a)+\gamma V^{\pi}(s’) - V^{\pi}(s)$来辅助更新策略函数的参数,这里使用值函数作为一种baseline,降低了实际更新时参数的方差,advantage函数可看作在状态s采取行动a时,相对于当前状态值函数的一种优势。因为值函数是对状态未来预期价值的一种估计。于是,这里$\theta$的更新公式变成$\theta \leftarrow \theta + (\sum\limits_{t=1}^{T}\triangledown_{\theta}log\pi(a_{t}|s_{t}; \theta))(\sum\limits_{t=1}^{T}(r(s_{t},a_{t})+\gamma V^{\pi}(s_{t+1}) - V^{\pi}(s_{t})))$。当然Advantage函数的形式不只这一种,具体可参考[2]。
2.2 值网络
- 在上述的Actor-Critic框架中,值网络$V(s, \theta’)$主要用来辅助策略网络的参数$\theta$的更新;同时,值网络同样需要进行训练,值网络的参数更新公式为:$\theta’ \rightarrow \theta’ + \partial(r_{t}-V(s_{t}, \theta’))^{2}/\partial \theta’$
3. A3C算法
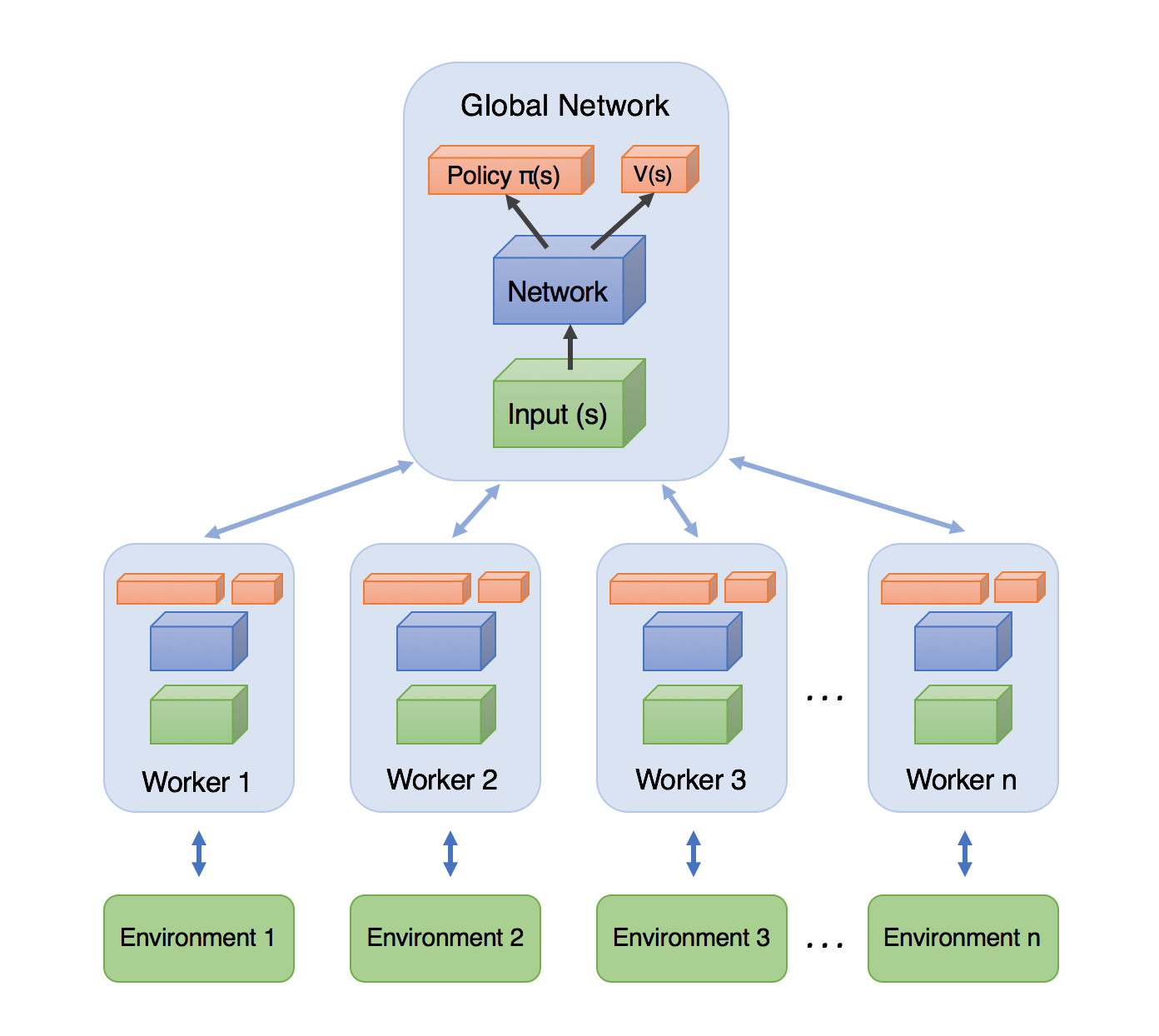
在上述的算法流程图和示意图[3]中,值得注意的关键点有:
- 有一个中央控制大脑Global Network,存储着全局参数,负责异步接收各个agent(Worker)的参数梯度来更新全局参数。
- 各个agent同步中央大脑的参数到自身,再各自进行单独的actor训练。每个agent都先根据策略网络进行训练数据的收集,再累积多个时间步的批量样本来更新策略网络和值网络,这样保证了训练的稳定性。
4. 代码实现[4]
下面以经典Atari游戏中的Breakout为例,基于tensorflow给出整个A3C算法的代码,超参数定义部分省略。
4.1 定义网络结构
1 |
|
上述代码中定义了策略网络和值网络的结构、损失值、梯度值。
4.2 定义各个Agent
1 |
|
上述代码定义了每个Agent同步来自全局大脑的参数、梯度累积、数据收集、独自训练、效果测试的过程。
4.3 执行实际的训练过程
1 |
|
上述代码定义了中央大脑和各个训练Worker,启动整个网络的训练。
参考资料
[1] Asynchronous Methods for Deep Reinforcement Learning
[2] High-Dimensional Continuous Control Using Generalized Advantage Estimation
[3] Simple Reinforcement Learning with Tensorflow Part 8: Asynchronous Actor-Critic Agents (A3C)
[4] Github上A3C算法的实现
