1. 原始记忆网络(Memory Network)
由FAIR的Jason Weston等在2015年提出,主要应用于文本问答任务中,相比之前的方法,在F1值上取得了显著的提升。核心思想是考虑到典型的循环神经网络(如Valinna-RNN、LSTM、GRU)依赖状态向量进行序列状态的记忆,记忆能力受限,很难记忆过去的一些事实;因而增加单独的、可以读写的记忆组件。
1.1 模型结构
- 输入组件$I$对输出的原始数据进行特征变换。
- 记忆组件$G$就是对输入的特征向量进行存储的槽;每次一个输入进来时,更新已有的记忆槽。
- 输出组件$O$根据输入选择匹配的记忆,并结合输入和记忆产生最终的输出。
- 回复组件根据输出$O$产生最终的回复结果。
- 整个模型的flow分为四步:
- 输入转换:$x \rightarrow I(x)$
- 根据新输入更新记忆:$m_{i}=G(m_{i}, I(x), m)$
- 输出计算:$o=O(I(x), m)$
- 根据输出产生最终的回复: $r=R(o)$
1.2 文本问答
- 针对文本问答任务,核心的推理在输出O和回复R模块。
- O模块选取k(k=2)个辅助推理的记忆内容:$o_{j}=\arg\max\limits_{i=1,2,…,N}s_{O}(x, m_{i}), j=1,2,…,k$
- R模块选取最终回复的词:$r=\arg\max_{w \in W}s_{R}([x,m_{o_{1}},m_{o_{2}}], w)$,$W$代表词典中所有词。
- 打分函数:$s(x,y)=\Phi_{x}(x)^{T}U^{T}U\Phi_{y}(y)$,$\Phi$用来对输入进行特征映射,$U$是需要学习的权重矩阵。
- 训练目标函数
- 这里采用的是类似SVM中的最大边缘损失函数。
2.动态记忆网络(Dynamic Memory Network)
由Ankit Kumar等在2016年提出,并指出很多NLP任务可以看作QA任务。DMN在文本问答、文本分类、词性标注几个不同的任务中都取得了很好的效果。
2.1 模型架构
- 单独的情景记忆模块:情景记忆模块通常需要多轮迭代更新,实验结果显示多轮迭代对于需要推理的任务十分重要,下图中的两条线代表两次阅读输入事实,迭代次数也是个需要调整的超参数。每一轮的内容$e_{i}$根据输入事实的表征$c_{t}$、输入问题的表征$q$以及之前的记忆$m_{i-1}$来产生。
- $h_{t}^{i} = g_{t}^{i}GRU(c_{t}, h_{t-1}^{i})+(1-g_{t}^{i})h_{t-1}^{i}$
- $e^{i} = h_{T_{C}}^{i}$,$T_{C}$是输入事实的个数
- 记忆模块:根据之前的记忆内容、问题表征、情景记忆内容来产生。记忆表征初始化为$m^{0}=q$。
- $m^{i} = GRU(e^{i}, m_{i-1})$
- 输入表征、问题表征以及答案的产生均基于GRU。
采用了注意力机制来计算事实表征$c$、内部记忆$m$和问题表征$q$之间的匹配得分值。整体来说,attention的计算较为复杂。
- $z(c,m,q)=[c, m, q, c\circ q, |c-q|, |c-m|, c^{T}W^{(b)}q, c^{T}W^{(b)}m]$
- $G(c,m,q)=\sigma(W^{(2)}tanh(W^{(1)}z(c,m,q)+b^{(1)})+b^{(2)})$
- $g_{t}^{i} = G(c_{t}, m^{i-1}, q)$
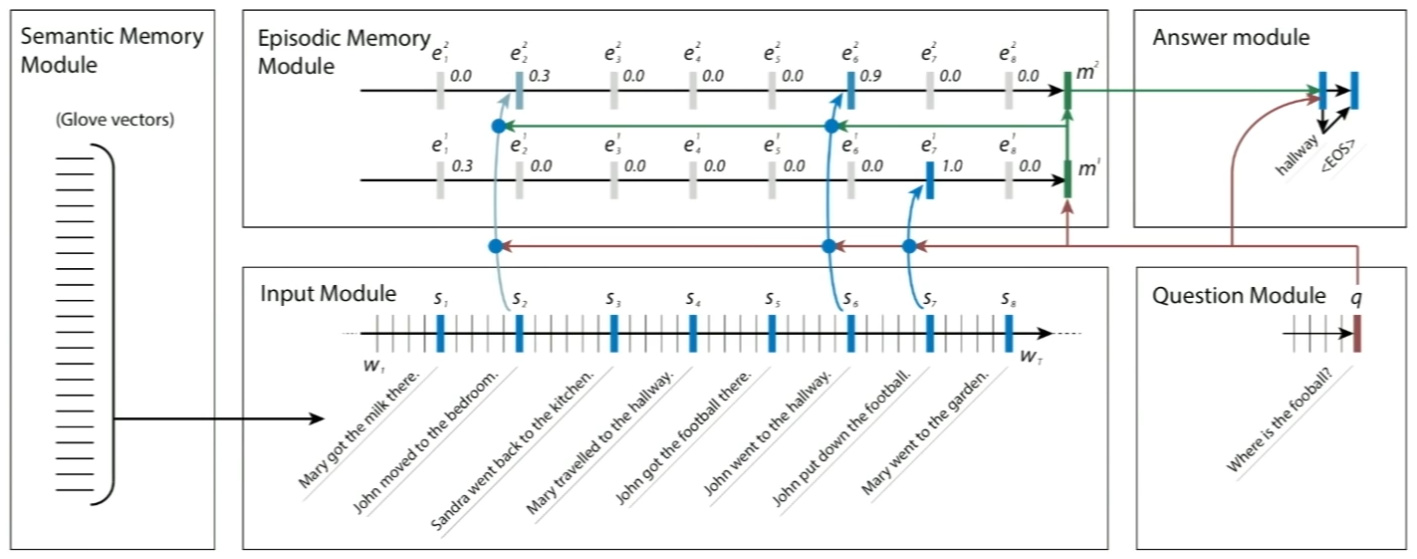
相比记忆网络,动态记忆网络增加了attention机制,并且记忆内容端到端可微。
2.2 代码实现
整个DMN的代码如下,详细功能参考注释
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244class DynamicMemoryNetwork(object):
'''
定义动态记忆网络的结构
'''
def __init__(self, config):
self.config = config #针对整个网络超参数的配置
if self.config.train_mode:
self.train, self.valid, self.word_embedding, self.max_q_len, self.max_sentences, self.max_sen_len, \
self.num_supporting_facts, self.vocab_size = babi_input.load_babi(self.config, split_sentences=True)
else:
self.test, self.word_embedding, self.max_q_len, self.max_sentences, self.max_sen_len, \
self.num_supporting_facts, self.vocab_size = babi_input.load_babi(self.config, split_sentences=True)
self.question_holder = tf.placeholder(tf.int32, shape=(self.config.batch_size, self.max_q_len))
self.input_placeholder = tf.placeholder(tf.int32, shape=(self.config.batch_size, self.max_sentences, self.max_sen_len))
self.question_len_holder = tf.placeholder(tf.int32, shape=(self.config.batch_size, ))
self.input_len_holder = tf.placeholder(tf.int32, shape=(self.config.batch_size, ))
self.answer_holder = tf.placeholder(tf.int64, shape=(self.config.batch_size, ))
self.rel_label_holder = tf.placeholder(tf.int32, shape=(self.config.batch_size, self.num_supporting_facts))
self.dropout_placeholder = tf.placeholder(tf.float32)
encoding = np.ones((self.config.embed_size, self.max_sen_len), dtype=np.float32)
for i in range(1, self.config.embed_size+1):
for j in range(1, self.max_sen_len+1):
encoding[i-1, j-1] = (i - (self.config.embed_size-1)/2)*(j - (self.max_sen_len-1)/2)
encoding = 1 + 4 * encoding / (self.config.embed_size*self.max_sen_len)
self.encoding = np.transpose(encoding)
self.embeddings = tf.Variable(self.word_embedding.astype(np.float32), name="embedding")
self.output = self.inference()
self.pred = self.get_predictions(self.output)
self.calculate_loss = self.add_loss_op(self.output)
self.train_step = self.add_training_op(self.calculate_loss)
self.merged = tf.summary.merge_all()
def get_input_represetation(self):
'''
计算输入事实的表征
:return:
'''
inputs = tf.nn.embedding_lookup(self.embeddings, self.input_placeholder)
inputs = tf.reduce_sum(inputs*self.encoding, 2)
forward_gru_cell = tf.contrib.rnn.GRUCell(self.config.hidden_size)
backward_gru_cell = tf.contrib.rnn.GRUCell(self.config.hidden_size)
outputs, _ = tf.nn.bidirectional_dynamic_rnn(
forward_gru_cell,
backward_gru_cell,
inputs,
dtype=np.float32,
sequence_length=self.input_len_holder
)
fact_vecs = tf.reduce_sum(tf.stack(outputs), axis=0)
fact_vecs = tf.nn.dropout(fact_vecs, self.dropout_placeholder)
return fact_vecs
def get_question_representation(self):
'''
计算输入问题的表征
:return:
'''
questions = tf.nn.embedding_lookup(self.embeddings, self.question_holder)
gru_cell = tf.contrib.rnn.GRUCell(self.config.hidden_size)
_, q_vec = tf.nn.dynamic_rnn(
gru_cell,
questions,
dtype=np.float32,
sequence_length=self.question_len_holder
)
return q_vec
def get_attention(self, q_vec, fact_vec, prev_memory, reuse):
'''
计算注意力分值
:param q_vec:
:param fact_vec:
:param prev_memory:
:param reuse:
:return:
'''
with tf.variable_scope('attention', reuse=reuse):
features = [fact_vec*q_vec, fact_vec*prev_memory, tf.abs(fact_vec - q_vec), tf.abs(fact_vec - prev_memory)]
feature_vec = tf.concat(features, 1)
attention = tf.contrib.layers.fully_connected(feature_vec,
self.config.embed_size,
activation_fn=tf.nn.tanh,
reuse=reuse,
scope='fc1')
attention = tf.contrib.layers.fully_connected(attention,
1,
activation_fn=None,
reuse=reuse,
scope='fc2')
return attention
def generate_episode(self, memory, q_vec, fact_vecs, hop_index):
'''
计算下一轮的情景记忆内容
:param memory:
:param q_vec:
:param fact_vecs:
:param hop_index:
:return:
'''
attentions = [tf.squeeze(self.get_attention(q_vec, memory, fv, bool(hop_index) or bool(i)), axis=1)
for i, fv in enumerate(tf.unstack(fact_vecs, axis=1))]
attentions = tf.transpose(tf.stack(attentions))
self.attentions.append(attentions)
attentions = tf.nn.softmax(attentions)
attentions = tf.expand_dims(attentions, axis=-1)
reuse = True if hop_index > 0 else False
print('fact_vecs:', fact_vecs.shape)
print('attentions:', attentions.shape)
gru_inputs = tf.concat([fact_vecs, attentions], 2)
print('gru_inputs:', gru_inputs.shape)
with tf.variable_scope('attention_gru', reuse=reuse):
_, episode = tf.nn.dynamic_rnn(
AttentionGRUCell(self.config.hidden_size),
gru_inputs,
dtype=np.float32,
sequence_length=self.input_len_holder
)
return episode
def add_answer_module(self, rnn_output, q_vec):
'''
计算答案
:param rnn_output:
:param q_vec:
:return:
'''
rnn_output = tf.nn.dropout(rnn_output, self.dropout_placeholder)
output = tf.layers.dense(
tf.concat([rnn_output, q_vec], 1),
self.vocab_size,
activation=None
)
return output
def inference(self):
'''
根据记忆内容计算输出表征
:return:
'''
with tf.variable_scope('question', initializer=tf.contrib.layers.xavier_initializer()):
q_vec = self.get_question_representation()
with tf.variable_scope('input', initializer=tf.contrib.layers.xavier_initializer()):
fact_vecs = self.get_input_represetation()
self.attentions = []
with tf.variable_scope('memory', initializer=tf.contrib.layers.xavier_initializer()):
prev_memory = q_vec
for i in range(self.config.num_hops):
episode = self.generate_episode(prev_memory, q_vec, fact_vecs, i)
with tf.variable_scope('hop_%d' % i):
prev_memory = tf.layers.dense(
tf.concat([prev_memory, episode, q_vec], 1),
self.config.hidden_size,
activation=tf.nn.relu
)
output = prev_memory
with tf.variable_scope('answer', initializer=tf.contrib.layers.xavier_initializer()):
output = self.add_answer_module(output, q_vec)
return output
def get_predictions(self, output):
preds = tf.nn.softmax(output)
return tf.argmax(preds, 1)
def add_loss_op(self, output):
gate_loss = 0
if self.config.strong_supervision:
for i, attention in enumerate(self.attentions):
labels = tf.gather(tf.transpose(self.rel_label_holder), 0)
gate_loss += tf.reduce_sum(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=attention, labels=labels))
loss = self.config.beta*tf.reduce_sum(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=output, labels=self.answer_holder)) + gate_loss
for v in tf.trainable_variables():
if not 'bias' in v.name.lower():
loss += self.config.l2 * tf.nn.l2_loss(v)
tf.summary.scalar('loss', loss)
return loss
def add_training_op(self, loss):
optimizer = tf.train.AdamOptimizer(learning_rate=self.config.lr)
grad_and_vars = optimizer.compute_gradients(loss)
if self.config.clip_grads:
grad_and_vars = [(tf.clip_by_norm(grad, self.config.max_grad_value), var) for grad, var in grad_and_vars]
train_op = optimizer.apply_gradients(grad_and_vars)
return train_op
def run_epoch(self, session, data, num_epoch=0, train_writer=None, train_op=None, verbose=2, train=False):
'''
计算训练集或测试集当前epoch的平均损失和准确率
:param session:
:param data:
:param num_epoch:
:param train_writer:
:param train_op:
:param verbose:
:param train:
:return:
'''
dropout = self.config.dropout
total_steps = len(data[0])
total_loss = []
accuracy = 0
p = np.random.permutation(len(data[0]))
qp, ip, ql, il, im, a, r = data
qp, ip, ql, il, im, a, r = qp[p], ip[p], ql[p], il[p], im[p], a[p], r[p]
for step in range(total_steps/self.config.batch_size):
index = range(step*self.config.batch_size, (step+1)*self.config.batch_size)
feed = {
self.question_holder: qp[index],
self.input_placeholder: ip[index],
self.question_len_holder: ql[index],
self.input_len_holder: il[index],
self.answer_holder: a[index],
self.rel_label_holder: r[index],
self.dropout_placeholder: dropout
}
if train_op is not None:
loss, pred, summary, _ = session.run([self.calculate_loss, self.pred, self.merged, train_op],
feed_dict=feed)
else:
loss, pred, summary = session.run([self.calculate_loss, self.pred, self.merged], feed_dict=feed)
if train_writer is not None:
train_writer.add_summary(summary, num_epoch*total_steps+step)
answers = a[step*self.config.batch_size:(step+1)*self.config.batch_size]
accuracy += np.sum(answers==pred)/len(answers)
total_loss.append(loss)
return np.mean(total_loss), accuracy/float(total_steps)基于注意力机制的AttentionGRUCell类的代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55class AttentionGRUCell(RNNCell):
'''
基于Attention机制的GRUCell实现
'''
def __init__(self, num_units, activation=tanh):
RNNCell.__init__(self)
self._num_units = num_units
self._activation_fn = activation
@property
def output_size(self):
return self._num_units
@property
def state_size(self):
return self._num_units
def __call__(self, inputs, state, scope=None):
with tf.variable_scope(scope or 'attention_gru_cell'):
with tf.variable_scope('gates'):
inputs, z = tf.split(inputs, num_or_size_splits=[self._num_units, 1], axis=1)
r = self._linear([inputs, state], self._num_units, True)
r = tf.nn.sigmoid(r)
with tf.variable_scope('candidate'):
r = r * self._linear(state, self._num_units, False)
with tf.variable_scope('input'):
x = self._linear(inputs, self._num_units,True)
h_hat = self._activation_fn(r + x)
new_h = (1 - z) * state + z * h_hat
return new_h, new_h
def _linear(self, args, output_size, bias, bias_start=0.0):
if not nest.is_sequence(args):
args = [args]
total_arg_size = 0
shapes = [a.get_shape() for a in args]
for shape in shapes:
total_arg_size += shape[1].value
dtype = [a.dtype for a in args][0]
scope = tf.get_variable_scope()
with tf.variable_scope(scope) as outer_scope:
weights = tf.get_variable('weights', [total_arg_size, output_size], dtype=dtype)
if len(args) == 1:
res = tf.matmul(args[0], weights)
else:
res = tf.matmul(tf.concat(args, 1), weights)
if not bias:
return res
with tf.variable_scope(outer_scope) as inner_scope:
inner_scope.set_partitioner = None
biases = tf.get_variable('biases', [output_size], dtype=dtype,
initializer=tf.constant_initializer(bias_start, dtype=dtype))
return tf.nn.bias_add(res, biases)babi数据集的预处理、加载代码参考文末的参考资料链接[3]。
